We compare our low-level motion generator with the baseline: CNet+GRIP. While the baseline fails to produce precise hand and finger motions, our method successfully generates accurate hand-object interactions.
Abstract
Intelligent agents must autonomously interact with the environments to perform daily tasks based on human-level instructions. They need a foundational understanding of the world to accurately interpret these instructions, along with precise low-level movement and interaction skills to execute the derived actions. In this work, we propose the first complete system for synthesizing physically plausible, long-horizon human-object interactions for object manipulation in contextual environments, driven by human-level instructions. We leverage large language models (LLMs) to interpret the input instructions into detailed execution plans. Unlike prior work, our system is capable of generating detailed finger-object interactions, in seamless coordination with full-body movements. We also train a policy to track generated motions in physics simulation via reinforcement learning (RL) to ensure physical plausibility of the motion. Our experiments demonstrate the effectiveness of our system in synthesizing realistic interactions with diverse objects in complex environments, highlighting its potential for real-world applications.
Video
Method Overview
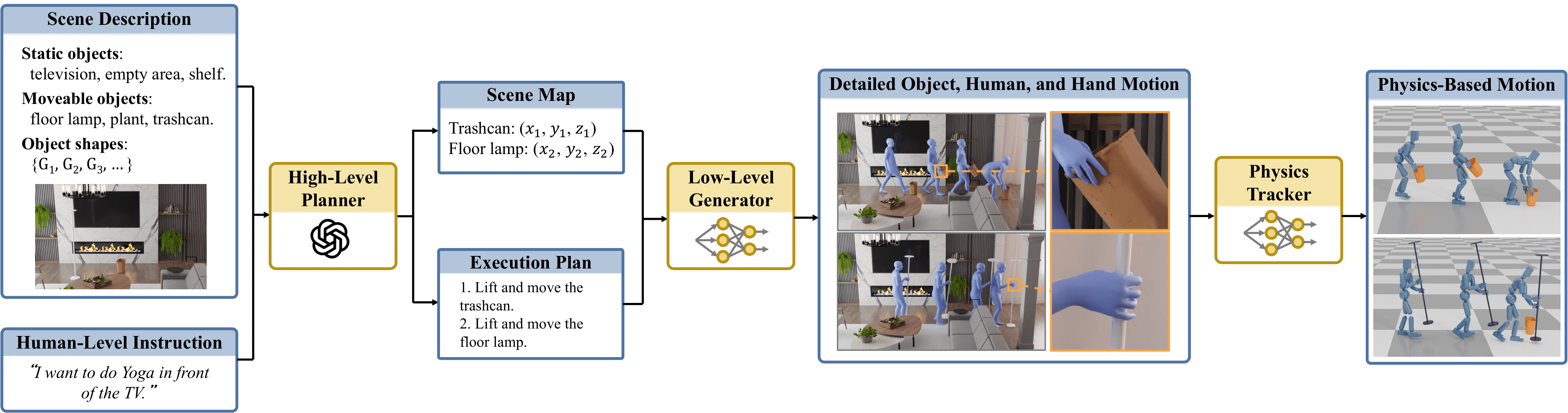
Our system takes the scene description and human-level instruction as input and uses a high-level planner to obtain the scene map and a detailed execution plan. The low-level motion generator then generates synchronized object motion, full-body human motion, and finger motion. Finally, the physics tracker uses RL to track the generated motion, producing physically plausible motion.